

Top 10 Web Scraping Techniques
In this comprehensive guide, we will explore a variety of web scraping techniques to help you unlock the power of data. From HTML parsing to API scraping and overcoming challenges like Captcha mechanisms, we’ll cover it all. So, let’s dive in and discover the world of web scraping!
There is an overwhelming amount of information available online, extracting, and organizing data manually can be a daunting task. This is where web scraping techniques come to the rescue.
In today’s digital age, data is the key to gaining insights, making informed decisions, and staying ahead of the competition. In this comprehensive guide, we will explore a variety of web scraping techniques to help you unlock the power of data.
From HTML parsing to API scraping and overcoming challenges like Captcha mechanisms, we’ll cover it all. So, let’s dive in and discover the world of web scraping!
Now let’s uncover the techniques that will help you out in web scraping.
Web Scraping Techniques
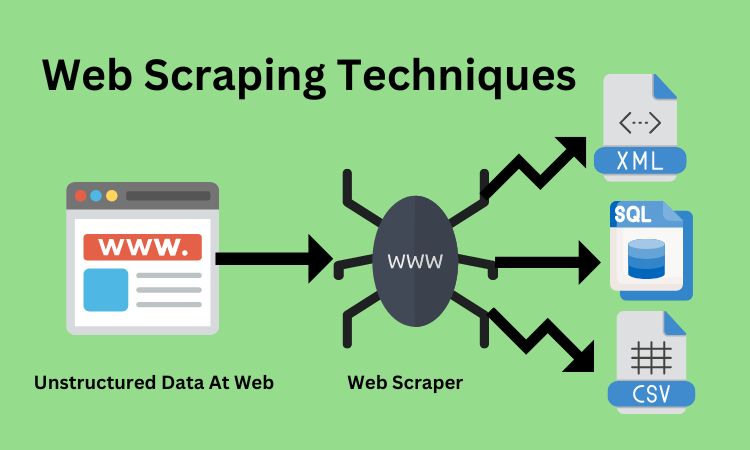
1-HTML Parsing
HTML parsing involves analyzing the structure and content of HTML documents to extract data. HTML parsing is one of the fundamental techniques in web scraping, as it allows you to scrape data from websites by traversing the HTML tree.
2-XPath
XPath is a language for navigating XML and HTML documents. It provides a way to address specific elements or attributes within an XML or HTML structure using path expressions. XPath is one of the best web scraping techniques when you need to extract data from complex or nested HTML structures.
3-CSS Selectors
CSS selectors are commonly used in web development to style HTML elements. CSS selectors are supported by libraries like Beautiful Soup, making it easy to integrate them into your web scraping workflow.
4-Regular Expressions
Regular expressions (regex) are powerful tools for pattern matching and data extraction. Regular expressions can be implemented using programming languages like Python, which offers a built-in re-module for regex operations.
5-API Scraping
Many websites provide APIs (Application Programming Interfaces) that allow developers to access and retrieve structured data. You need to understand the API documentation, authentication methods, and request parameters to successfully scrape data through APIs.
6-Headless Browsers
Headless browsers, such as Selenium or Puppeteer, are tools that allow you to automate web browsers. This allows you to access and extract data that would otherwise be challenging using traditional scraping techniques.
7-Captcha Solving
Captcha challenges are often used by websites to prevent automated scraping. For more complex Captchas, third-party services offer APIs that can handle the solving process. These services use machine learning algorithms or human experts to solve the challenges and provide the result to your scraping script.
8-Dynamic Content Handling
Some websites dynamically load content using JavaScript after the initial HTML request. By waiting for the dynamic content to load and extracting the desired information, you can effectively scrape data from dynamic websites.
9-Proxy Rotation
When scraping multiple pages or websites, it’s important to manage IP blocking or rate limiting that website may impose. Proxy rotation involves using multiple IP addresses or proxy servers to distribute your requests. By rotating proxies, you can avoid being detected as a scraper and increase your scraping efficiency.
10-Anti-scraping Countermeasures
Websites may implement measures to detect and prevent scrapings, such as IP blocking, rate limiting, or user-agent detection. Additionally, employing IP rotation or proxy servers can further mask your scraping activities.
Related: Web Scraping Challenges
Practices To Implement Web Scraping Techniques
Here you have three practices to keep in mind, before you extract data from any website.
i-Respect Website Boundaries
Website owners have the right to restrict or prohibit web scraping on their sites. Before scraping, review the website’s robots.txt file, Terms of Service, and Privacy Policy. If in doubt, seek permission from the site owners. Respect their boundaries and scraping guidelines.
ii-Maintain Ethical Data Usage
Ensure your web scraping activities are ethical and align with the website’s intentions. Avoid scraping sensitive or personally identifiable information that could invade privacy or contribute to identity theft.
iii-Ensure Copyright Compliance and Attribution
Remember that the data you scrape belongs to the website owners. Give credit where it’s due and refrain from using scraped data without proper attribution. Be cautious when sharing scraped information on social media or other platforms and ensure you link back to the original site when necessary.
Conclusion
In conclusion, web scraping techniques offer valuable solutions for extracting data from websites efficiently. By respecting website boundaries, maintaining ethical data usage, and ensuring copyright compliance and attribution, you can scrape data responsibly and legally.
Understanding various web scraping techniques, such as HTML parsing, XPath, CSS selectors, API scraping, and handling challenges like Captcha, allows you to gather specific data from websites effectively. Remember to approach web scraping with integrity and adherence to best practices to harness the power of data for informed decision-making.
FAQs
How do I locate and extract specific data from a website?
To extract specific data, you can use web scraping techniques like CSS selectors and XPath. With these techniques, you can target specific HTML elements and extract the desired information.
How can I deal with anti-scraping measures like CAPTCHA or IP blocking?
You can use techniques like rotating IP addresses, implementing delays between requests, or using CAPTCHA-solving services to overcome these anti-scraping measures.





